



AUJOURD'HUI, LA PRESQUE TOUTES LES ENTREPRISES DOIVENT ÊTRE DES ENTREPRISES TECHNOLOGIQUES - ce qui signifie qu'elles doivent être à la pointe de la technologie et de l'innovation si elles veulent rester compétitives et pertinentes. Et si le pétrole a été la ressource qui a alimenté l'industrialisation pendant de nombreuses générations, les données sont certainement le nouvel atout indispensable de notre économie de l'information. Des données saines, nettoyées et normalisées sont devenues le coût d'entrée pour faire des affaires dans la plupart des secteurs, tout en servant de moyen important de différenciation et d'avantage concurrentiel.
L'apprentissage automatique et l'intelligence artificielle générative (IA) donnent un coup de fouet à ce que les données peuvent faire. Une nouvelle analyse du McKinsey Global Institute estime que l'IA générative pourrait ajouter l'équivalent de 2,6 à 4,4 billions de dollars par an. En permettant la capture, l'extraction et la manipulation de données à grande échelle et à grande vitesse, l'IA générative a introduit le potentiel de remodeler fondamentalement les industries de la connaissance.
La position de State Street dans l'industrie des services financiers nous place à la convergence de la technologie et de l'innovation, des produits et des opérations. En tant qu'institution hautement réglementée, State Street est en mesure de tirer parti de ses 231 ans d'histoire, ainsi que de sa taille, de son échelle et de son histoire de gérance, pour apporter des innovations technologiques précoces telles que la blockchain et la tokenisation des actifs financiers aux clients et à l'industrie des services financiers dans son ensemble. Notre rôle en tant que GSIB (banque mondiale d'importance systémique) nous offre un point de vue unique pour assister à notre moment actuel et à la transformation du paysage mondial de l'investissement induite par la technologie qui est en cours. Qu'observons-nous donc à ce moment critique de l'innovation technologique ? Étant donné que les données sont le carburant de toute activité d'IA, l'opportunité que représente aujourd'hui l'IA pour le secteur des services financiers souligne l'importance pour les entreprises de mettre en place un programme de transformation des données rigoureux et fiable. La recherche montre que les entreprises qui ont mis en place une stratégie holistique en matière de données bénéficient déjà d'avantages significatifs au niveau de divers indicateurs de performance.
Un rapport récemment publié par State Street, " Capturing the Data Opportunity : Institutional Investors in the Age of AI", examine l'opportunité des données à l'ère de l'IA pour les investisseurs institutionnels du monde entier. Première étude complète à quantifier l'opportunité des données en termes économiques, le rapport présente des recherches basées sur une enquête menée auprès de plus de 500 propriétaires d'actifs, gestionnaires d'actifs, gestionnaires de patrimoine, institutions officielles et assureurs du monde entier. Il offre un aperçu approfondi de l'état d'avancement de la transformation des données dans les entreprises, des défis auxquels elles sont confrontées et des outils dont elles disposent.
Selon les résultats de l'enquête, plus de 80 % des institutions financières interrogées considèrent que l'amélioration de la gestion et de l'utilisation des données représente une opportunité "moyenne", "importante" ou "transformationnelle". Cela dit, l'enquête a révélé un résultat très surprenant : alors que les entreprises interrogées ayant une stratégie de données ont signalé en moyenne une augmentation de 24% de la satisfaction des clients, une augmentation de 21% de la rétention des clients, une augmentation de 19% de l'acquisition de nouveaux clients et une augmentation de 19% de la croissance des revenus, au moins deux tiers des entreprises participantes ont signalé l'absence d'une stratégie de données globale, les propriétaires d'actifs étant à la traîne par rapport aux catégories d'institutions financières interrogées. Notre enquête a également mis en évidence les domaines dans lesquels les investisseurs institutionnels s'attendent à ce que l'IA apporte le plus de valeur au cours des deux à cinq prochaines années, à savoir :
- CYBERSECURITE AMÉLIORÉE
Utilisation de l'IA pour analyser le trafic réseau, détecter les anomalies et identifier de manière proactive les menaces potentielles. - ANALYSE AUTOMATIQUE DES INVESTISSEMENTS
Y compris la collecte de données, l'analyse des tendances et la modélisation prédictive. - EXPERIENCE CLIENTÈLE ET ENGAGEMENT
Utilisation de chatbots et d'assistants virtuels alimentés par l'IA pour améliorer l'expérience client grâce à des requêtes en langage naturel. - ANALYSE DES RISQUES
Facteurs de risque générés par l'IA qui complètent les facteurs fondamentaux macroéconomiques, statistiques et
existants. - CONSEILS D'INVESTISSEMENT PERSONNALISÉS
Utilisation d'algorithmes d'IA pour analyser les profils d'investisseurs individuels, les préférences et les tendances du marché afin de fournir des conseils personnalisés.
Il convient de noter ici que même si l'on a l'impression que la technologie de l'IA est née l'année dernière, étant donné toute l'attention portée à ChatGPT et à d'autres chatbots populaires, de nombreuses applications de l'IA existent depuis la fin des années 1950. Parmi les exemples courants connus de tous, citons l'identification des visages et la reconnaissance d'images, les chatbots qui imitent les personnes dans les messages textuels ou enregistrés du service clientèle, et les systèmes experts tels que les véhicules autopilotés et les ordinateurs jouant aux échecs.
State Street développe des fonctionnalités d'IA depuis plus de cinq ans et compte des centaines de praticiens de l'IA. L'exploitation des promesses de l'IA a contribué à nos efforts de transformation et a permis d'améliorer la qualité, la précision et la rapidité des services. Nous avons utilisé l'apprentissage automatique pour améliorer ou automatiser les processus existants afin de réduire le travail manuel et d'augmenter l'efficacité de manière à libérer la capacité de nos employés à effectuer un travail plus stratégique et à plus fort impact.
En tant qu'entreprise axée sur la technologie, nous considérons l'IA comme un moyen d'accélérer notre programme d'innovation. Nous étudions attentivement la manière dont l'IA peut contribuer à renforcer l'efficacité dans l'ensemble de l'entreprise, à améliorer l'expérience des clients, à offrir de meilleures opportunités à nos employés et à mettre en place une organisation plus rationnelle et plus productive au profit de toutes nos parties prenantes. Parmi les utilisations potentielles que nous étudions actuellement, citons les moyens d'intégrer l'IA dans les rapports de dépenses (pour remplir automatiquement les soumissions scannées et signaler les soumissions aberrantes), l'amélioration du processus d'appel d'offres (pour automatiser les réponses et générer du matériel de marketing adapté et spécifique au segment), la gestion des demandes (pour réduire les efforts manuels) et l'intelligence documentaire (pour accélérer l'extraction d'informations et de données clés).
Alors que l'adoption de l'IA continue de croître, la manière de mettre en œuvre cette technologie de manière réfléchie est devenue aussi importante que ce qu'il faut en faire. Chez State Street, notre approche de l'IA responsable repose sur les quatre domaines suivants :
- ÉTHIQUE
Garantir l'équité et éviter les préjugés grâce à des échantillons représentatifs équilibrés pour chaque classe cible et à l'exploitation d'un étiquetage diversifié des données. - VIE PRIVÉE ET SÉCURITÉ
Protéger les données contre les risques de sécurité propres à l'utilisation de l'IA - TRANSPARENCE, EXPLAÇABILITÉ, SUIVI
Comment les systèmes d'IA sont conçus, sur quelles données ils sont formés et comment ils sont déployés et suivis. Il convient également d'être transparent quant aux limites de la technologie et aux cas d'utilisation appropriés. - RESPONSABILITÉ
Établir des lignes claires de responsabilité, de gouvernance et de contrôle.
Une partie intégrante de l'IA responsable est la responsabilité à l'égard de notre personnel. S'il est vrai que notre industrie est sur le point de connaître une évolution majeure, il est essentiel de se rappeler que l'IA n'est encore qu'un outil. Comme la calculatrice, l'ordinateur ou l'internet avant elle, l'IA est une innovation qui ne sera aussi intelligente et performante que les personnes et les équipes qui mettent la technologie en œuvre.
Les grandes institutions financières internationales cotées en bourse ont l'obligation de servir leurs actionnaires et les autres parties prenantes, notamment les clients, les employés, les partenaires, les fournisseurs et les communautés dans lesquelles elles vivent et travaillent. Une partie de cette responsabilité consiste à présenter les nouvelles technologies et les innovations aux investisseurs de manière à les familiariser avec les possibilités offertes par ces avancées, et à intégrer de manière réfléchie les nouvelles technologies dans l'écosystème plus large des services financiers.
Notre secteur est aujourd'hui très intéressé par l'utilisation de la technologie révolutionnaire de l'IA pour transformer les modèles opérationnels et aider les investisseurs à prendre des décisions d'investissement plus éclairées. Alors que nous utilisons l'IA pour moderniser et "préparer l'avenir" de nos propres modèles opérationnels, les clients et les autres parties prenantes attendent de nous que nous intégrions de manière réfléchie les nouvelles technologies dans l'écosystème des services financiers et que nous les mettions en relation avec la communauté des investisseurs institutionnels au sens large. Nous faisons ce travail en sachant que l'expertise et la perspicacité humaines, l'engagement et les relations personnelles avec les clients, ainsi que le type de prise de décision qui découle de la profondeur de l'expérience, restent irremplaçables.
Cet article a été rédigé par Neil Savage et publié à l'origine dans Nature
Bing Liu était en train de tester une voiture autonome sur la route, quand soudain quelque chose a mal tourné. Le véhicule fonctionnait sans problème jusqu'à ce qu'il atteigne un carrefour en T et refuse de bouger. Bing Liu et les autres occupants de la voiture étaient déconcertés. La route sur laquelle ils se trouvaient était déserte, sans piétons ni autres voitures en vue. "Nous avons regardé autour de nous, nous n'avons rien remarqué à l'avant, ni à l'arrière. Il n'y avait rien", raconte Liu, ingénieur informaticien à l'université de l'Illinois à Chicago.
Déconcertés, les ingénieurs ont pris le contrôle du véhicule et sont retournés au laboratoire pour faire le point sur le voyage. Ils ont découvert que la voiture avait été arrêtée par un caillou sur la route. Ce n'était pas quelque chose qu'une personne aurait pu remarquer, mais lorsqu'il est apparu sur les capteurs de la voiture, il a été enregistré comme un objet inconnu - quelque chose que le système d'intelligence artificielle (IA) qui conduisait la voiture n'avait jamais rencontré auparavant.
Partie de Nature Outlook : Robotique et intelligence artificielle
Le problème n'était pas lié à l'algorithme de l'IA en tant que tel - il fonctionnait comme prévu, s'arrêtant à proximité de l'objet inconnu par mesure de sécurité. Le problème était qu'une fois que l'IA avait terminé son entraînement, en utilisant des simulations pour développer un modèle qui lui permettait de faire la différence entre une route dégagée et un obstacle, elle ne pouvait plus rien apprendre. Lorsqu'elle rencontrait quelque chose qui ne faisait pas partie de ses données d'entraînement, comme un caillou ou même une tache sombre sur la route, l'IA ne savait pas comment réagir. Les gens peuvent s'appuyer sur ce qu'ils ont appris et s'adapter à l'évolution de leur environnement ; la plupart des systèmes d'IA sont enfermés dans ce qu'ils savent déjà.
Dans le monde réel, bien sûr, des situations inattendues surviennent inévitablement. C'est pourquoi Liu affirme que tout système visant à effectuer des tâches apprises en dehors d'un laboratoire doit être capable d'apprendre sur le tas, c'est-à-dire de compléter le modèle qu'il a déjà développé avec les nouvelles données qu'il rencontre. La voiture pourrait, par exemple, détecter une autre voiture traversant sans problème une zone sombre de la route et décider de l'imiter, apprenant par la même occasion qu'une partie humide de la route ne pose pas de problème. Dans le cas du caillou, il pourrait utiliser une interface vocale pour demander à l'occupant de la voiture ce qu'il doit faire. Si le conducteur répond qu'il peut continuer en toute sécurité, la voiture peut continuer à rouler, et le système peut ensuite s'appuyer sur cette réponse lors de la prochaine rencontre avec un caillou. "Si le système peut apprendre en permanence, ce problème est facilement résolu", explique M. Liu.

Cet apprentissage continu, également appelé apprentissage tout au long de la vie, constitue la prochaine étape de l'évolution de l'IA. Une grande partie de l'IA repose sur les réseaux neuronaux, qui prennent des données et les font passer par une série d'unités de calcul, appelées neurones artificiels, qui exécutent de petites fonctions mathématiques sur les données. Le réseau finit par élaborer un modèle statistique des données qu'il peut ensuite adapter à de nouvelles entrées. Les chercheurs, qui ont basé ces réseaux neuronaux sur le fonctionnement du cerveau humain, se tournent à nouveau vers l'homme pour s'inspirer de la manière de créer des systèmes d'intelligence artificielle capables de continuer à apprendre au fur et à mesure qu'ils rencontrent de nouvelles informations. Certains groupes tentent de rendre les neurones informatiques plus complexes afin qu'ils ressemblent davantage aux neurones des organismes vivants. D'autres imitent la croissance de nouveaux neurones chez l'homme afin que les machines puissent réagir aux nouvelles expériences. D'autres encore simulent des états de rêve pour surmonter le problème de l'oubli. L'apprentissage tout au long de la vie est nécessaire non seulement pour les voitures autonomes, mais aussi pour tout système intelligent qui doit faire face à des surprises, comme les chatbots, qui sont censés répondre à des questions sur un produit ou un service, et les robots qui peuvent se déplacer librement et interagir avec les humains. Dhireesha Kudithipudi, informaticien qui dirige le MATRIX AI Consortium for Human Well-Being à l'université du Texas à San Antonio, estime que "dans pratiquement tous les cas où l'on déploiera l'IA à l'avenir, on constatera la nécessité d'un apprentissage tout au long de la vie".
L'apprentissage continu sera nécessaire pour que l'IA soit vraiment à la hauteur de son nom. À ce jour, l'IA n'est pas vraiment intelligente", déclare Hava Siegelmann, informaticienne à l'université du Massachusetts Amherst, qui a créé l'initiative de financement de la recherche "Lifelong Learning Machines" pour l'Agence américaine des projets de recherche avancée de défense. "S'il s'agit d'un réseau neuronal, vous l'entraînez à l'avance, vous lui donnez un ensemble de données et c'est tout. Il n'a pas la capacité de s'améliorer avec le temps".
Modélisation
Au cours de la dernière décennie, les ordinateurs sont devenus compétents dans des tâches telles que la classification de chats ou de tumeurs dans des images, l'identification de sentiments dans le langage écrit et la victoire aux échecs. Les chercheurs peuvent, par exemple, donner à l'ordinateur des photos qui ont été étiquetées par des humains comme contenant des chats. L'ordinateur reçoit les photos, qu'il interprète comme des descriptions numériques de pixels avec différentes valeurs de couleur et de luminosité, et les fait passer par des couches de neurones artificiels. Chaque neurone a un poids choisi au hasard, une valeur par laquelle il multiplie la valeur des données d'entrée. L'ordinateur fait passer les données d'entrée par les couches de neurones et vérifie les données de sortie par rapport aux données de validation afin de déterminer la précision des résultats. Il répète ensuite le processus, en modifiant les poids à chaque itération jusqu'à ce que la sortie atteigne un niveau de précision élevé. Ce processus produit un modèle statistique des valeurs et de l'emplacement des pixels qui définissent un chat. Le réseau peut alors analyser une nouvelle photo et décider si elle correspond au modèle, c'est-à-dire s'il y a un chat sur la photo. Mais ce modèle de chat, une fois élaboré, est pratiquement gravé dans le marbre.
Pour que l'ordinateur apprenne à identifier de nombreux objets, il faudrait développer de nombreux modèles. Vous pourriez entraîner un réseau neuronal à reconnaître les chats et un autre à reconnaître les chiens. Cela nécessiterait deux ensembles de données, un pour chaque animal, et doublerait le temps et la puissance de calcul nécessaires au développement de chaque modèle. Mais supposons que vous souhaitiez que l'ordinateur fasse la distinction entre les photos de chats et de chiens. Il faudrait alors former un troisième réseau, soit en utilisant toutes les données initiales, soit en comparant les deux modèles existants. Si l'on ajoute d'autres animaux, il faudra encore développer d'autres modèles.
La formation et le stockage d'un plus grand nombre de modèles nécessitent des ressources plus importantes, ce qui peut rapidement devenir un problème. La formation d'un réseau neuronal peut nécessiter des quantités de données et des semaines de temps. Par exemple, un système d'IA appelé GPT-3, qui a appris à produire un texte qui sonne comme s'il avait été écrit par un humain, a nécessité près de 15 jours de formation sur 10 000 processeurs d'ordinateurs haut de gamme1. L'ensemble de données ImageNet, souvent utilisé pour entraîner les réseaux neuronaux à la reconnaissance d'objets, contient plus de 14 millions d'images. Selon le sous-ensemble du nombre total d'images utilisé, le téléchargement peut prendre de quelques minutes à plus d'un jour et demi. Toute machine qui doit passer des jours à réapprendre une tâche chaque fois qu'elle rencontre de nouvelles informations s'immobilise.

Un système qui pourrait rendre la génération de modèles multiples plus efficace est Self-Net2créé par Rolando Estrada, informaticien à la Georgia State University d'Atlanta, et ses étudiants Jaya Mandivarapu et Blake Camp. Self-Net compresse les modèles afin d'éviter qu'un système contenant un grand nombre de modèles animaux différents ne devienne trop lourd.
Le système utilise un autoencodeur, un réseau neuronal distinct qui apprend quels paramètres - tels que les groupes de pixels dans le cas des tâches de reconnaissance d'images - le réseau neuronal original a pris en compte lors de la construction de son modèle. Une couche de neurones au milieu de l'autoencodeur oblige la machine à sélectionner un minuscule sous-ensemble des poids les plus importants du modèle. Il peut y avoir 10 000 valeurs numériques qui entrent dans le modèle et 10 000 autres qui en sortent, mais dans la couche centrale, l'autoencodeur réduit ces valeurs à 10 nombres seulement. Le système doit donc trouver les dix poids qui lui permettront d'obtenir le résultat le plus précis, explique M. Estrada.
Inscrivez-vous à la lettre d'information de Nature sur la robotique et l'IA
Le processus est similaire à la compression d'un grand fichier d'image TIFF en un fichier JPEG plus petit, explique-t-il ; il y a une légère perte de fidélité, mais ce qui reste est suffisamment bon. Le système élimine la plupart des données d'entrée originales, puis enregistre les dix meilleurs poids. Il peut ensuite les utiliser pour effectuer la même tâche d'identification des chats avec presque la même précision, sans avoir à stocker d'énormes quantités de données.
Pour rationaliser la création de modèles, les informaticiens ont souvent recours à la préformation. Les modèles formés pour effectuer des tâches similaires doivent apprendre des paramètres similaires, au moins dans les premières étapes. Un réseau neuronal qui apprend à reconnaître des objets dans des images, par exemple, doit d'abord apprendre à identifier les lignes diagonales et verticales. Il n'est pas nécessaire de repartir de zéro à chaque fois, de sorte que les nouveaux modèles peuvent être pré-entraînés avec les poids qui reconnaissent déjà ces caractéristiques de base. Pour créer des modèles capables de reconnaître des vaches, des cochons ou des kangourous, M. Estrada peut pré-entraîner d'autres réseaux neuronaux avec les paramètres de son autoencodeur. Étant donné que tous les animaux partagent certaines caractéristiques faciales, même si les détails de la taille ou de la forme sont différents, ce pré-entraînement permet de générer de nouveaux modèles plus efficacement.
Le système n'est pas un moyen parfait pour que les réseaux apprennent sur le tas, précise M. Estrada. Un humain doit encore indiquer à la machine quand changer de tâche, par exemple quand commencer à chercher des chevaux plutôt que des vaches. Pour ce faire, l'homme doit rester dans la boucle, et il n'est pas toujours évident pour lui de savoir qu'il est temps pour la machine de faire quelque chose de différent. Mais M. Estrada espère trouver un moyen d'automatiser le changement de tâche afin que l'ordinateur puisse apprendre à identifier les caractéristiques des données d'entrée et s'en servir pour décider du modèle à utiliser, de sorte qu'il puisse continuer à fonctionner sans interruption.

Fini l'ancien
Il peut sembler que la solution la plus évidente ne consiste pas à créer plusieurs modèles, mais plutôt à développer un réseau. Au lieu de développer deux réseaux pour reconnaître respectivement les chats et les chevaux, par exemple, il peut sembler plus facile d'apprendre au réseau qui reconnaît les chats à reconnaître également les chevaux. Cette approche oblige toutefois les concepteurs d'IA à se confronter à l'un des principaux problèmes de l'apprentissage tout au long de la vie, un phénomène connu sous le nom d'oubli catastrophique. Un réseau formé à la reconnaissance des chats développera un ensemble de poids sur ses neurones artificiels qui sont spécifiques à cette tâche. Si on lui demande ensuite d'identifier des chevaux, il commencera à réajuster les poids afin d'être plus précis pour les chevaux. Le modèle ne contiendra plus les bonnes pondérations pour les chats, ce qui l'amènera à oublier à quoi ressemble un chat. "La mémoire se trouve dans les poids. Lorsque vous l'entraînez avec de nouvelles informations, vous écrivez sur les mêmes poids", explique M. Siegelmann. "Vous pouvez avoir un milliard d'exemples de conduite d'une voiture, et maintenant vous lui enseignez 200 exemples liés à un accident que vous ne voulez pas voir se produire, et il se peut qu'il connaisse ces 200 cas et qu'il oublie le milliard.
L'une des méthodes permettant de surmonter l'oubli catastrophique consiste à rejouer, c'est-à-dire à prendre des données d'une tâche précédemment apprise et à les entrelacer avec de nouvelles données de formation. Toutefois, cette approche se heurte de plein fouet au problème des ressources. "Les mécanismes de relecture sont très gourmands en mémoire et en calcul, et nous ne disposons donc pas de modèles capables de résoudre ces problèmes de manière efficace en termes de ressources", explique M. Kudithipudi. Il peut également y avoir des raisons de ne pas stocker les données, par exemple pour des raisons de confidentialité ou de sécurité, ou parce qu'elles appartiennent à quelqu'un qui n'est pas disposé à les partager indéfiniment.
Selon M. Siegelmann, la relecture est à peu près analogue à ce que fait le cerveau humain lorsqu'il rêve. De nombreux neuroscientifiques pensent que le cerveau consolide les souvenirs et apprend des choses en rejouant ses expériences pendant le sommeil. De même, la relecture dans les réseaux neuronaux peut renforcer des poids qui pourraient autrement être écrasés. Mais le cerveau ne revoit pas ses expériences instant par instant, explique M. Siegelmann. Il réduit plutôt ces expériences à une poignée de caractéristiques et de modèles - un processus connu sous le nom d'abstraction - et ne rejoue que ces parties. La relecture inspirée par le cerveau de Mme Siegelmann tente de faire quelque chose de similaire ; au lieu de passer en revue des montagnes de données stockées, elle sélectionne certaines facettes de ce qu'elle a appris pour les rejouer. Selon Mme Siegelmann, chaque couche d'un réseau neuronal fait passer l'apprentissage à un niveau d'abstraction supérieur, depuis les données d'entrée spécifiques de la couche inférieure jusqu'aux relations mathématiques des données des couches supérieures. De cette manière, le système classe des exemples spécifiques d'objets dans des catégories. Elle laisse le réseau sélectionner les abstractions les plus importantes dans les deux couches supérieures et les rejouer. Cette technique permet de maintenir les poids appris raisonnablement stables - mais pas parfaitement - sans avoir à stocker les données précédemment utilisées.

Comme cette relecture inspirée du cerveau se concentre sur les points les plus saillants que le réseau a appris, ce dernier peut trouver plus facilement des associations entre les nouvelles et les anciennes données. La méthode aide également le réseau à distinguer des éléments de données qu'il n'aurait pas pu séparer facilement auparavant, par exemple en trouvant les différences entre une paire de jumeaux identiques. S'il n'y a plus qu'une poignée de paramètres dans chaque ensemble, au lieu de millions, il est plus facile de repérer les similitudes. "Maintenant, lorsque nous rejouons l'un avec l'autre, nous commençons à regarder les différences", explique M. Siegelmann. "Cela nous oblige à trouver la séparation, le contraste, les associations.
Se concentrer sur des abstractions de haut niveau plutôt que sur des éléments spécifiques est utile pour l'apprentissage continu, car cela permet à l'ordinateur de faire des comparaisons et des analogies entre différents scénarios. Par exemple, si votre voiture autonome doit déterminer comment conduire sur du verglas dans le Massachusetts, explique M. Siegelmann, elle pourrait utiliser les données dont elle dispose sur la conduite sur du verglas dans le Michigan. Ces exemples ne correspondront pas exactement aux nouvelles conditions, car ils concernent des routes différentes. Mais la voiture possède également des connaissances sur la conduite sur neige dans le Massachusetts, où les routes lui sont familières. Par conséquent, si la voiture peut identifier uniquement les différences et les similitudes les plus importantes entre la neige et la glace, le Massachusetts et le Michigan, au lieu de s'enliser dans des détails mineurs, elle pourrait trouver une solution à la situation spécifique et nouvelle de la conduite sur glace dans le Massachusetts.
Une approche modulaire
L'étude de la façon dont le cerveau traite ces questions peut inspirer des idées, même si elles ne reproduisent pas ce qui se passe biologiquement. Pour répondre au besoin d'un réseau neuronal capable d'apprendre des tâches sans écraser les anciennes, les scientifiques s'inspirent de la neurogenèse, le processus par lequel les neurones se forment dans le cerveau. Une machine ne peut pas se développer comme un corps, mais les informaticiens peuvent reproduire de nouveaux neurones dans un logiciel en générant des connexions dans certaines parties du système. Bien que les neurones matures aient appris à réagir à certaines données seulement, ces "bébés neurones" peuvent réagir à toutes les données. "Ils peuvent réagir aux nouveaux échantillons introduits dans le modèle", explique M. Kudithipudi. En d'autres termes, ils peuvent apprendre à partir de nouvelles informations tandis que les neurones déjà entraînés conservent ce qu'ils ont appris.
L'ajout de neurones n'est qu'un moyen parmi d'autres de permettre à un système d'apprendre de nouvelles choses. Estrada a proposé une autre approche, basée sur le fait qu'un réseau de neurones n'est qu'une approximation approximative d'un cerveau humain. Nous appelons les nœuds d'un réseau neuronal des "neurones". Mais si vous voyez ce qu'ils font réellement, ils calculent essentiellement une somme pondérée. C'est une vision incroyablement simplifiée des vrais neurones biologiques, qui effectuent toutes sortes de traitements de signaux non linéaires complexes".
Afin d'imiter avec plus de succès certains des comportements complexes des vrais neurones, Estrada et ses étudiants ont développé ce qu'il appelle des neurones artificiels profonds (DAN).3. Un DAN est un petit réseau neuronal qui est traité comme un seul neurone dans un réseau neuronal plus large.
Plus d'informations sur les perspectives de la nature
Les DAN peuvent être formés pour une tâche particulière - par exemple, Estrada pourrait en développer un pour identifier des chiffres manuscrits. Le modèle du DAN est alors fixé, de sorte qu'il ne peut être modifié et qu'il fournira toujours la même sortie aux autres neurones dans les couches du réseau toujours entraînables qui l'entourent. Ce réseau plus vaste peut continuer à apprendre une tâche connexe, telle que l'identification de chiffres écrits par quelqu'un d'autre, mais le modèle original n'est pas oublié. "On se retrouve avec un module polyvalent que l'on peut réutiliser pour des tâches similaires à l'avenir", explique M. Estrada. "Ces modules permettent au système d'apprendre à exécuter les nouvelles tâches de la même manière que les anciennes, de sorte que les fonctionnalités sont plus compatibles les unes avec les autres au fil du temps. Cela signifie que les fonctionnalités sont plus stables et qu'il y a moins d'oublis".
Jusqu'à présent, Estrada et ses collègues ont montré que cette technique fonctionne pour des tâches relativement simples, telles que la reconnaissance des nombres. Mais ils essaient de l'adapter à des problèmes plus complexes, notamment pour apprendre à jouer à de vieux jeux vidéo tels que Space Invaders. "Si nous y parvenons, nous pourrons l'utiliser pour des tâches plus sophistiquées", explique M. Estrada. Il pourrait, par exemple, s'avérer utile pour les drones autonomes, qui sont envoyés avec une programmation de base mais doivent s'adapter à de nouvelles données dans l'environnement, et devront effectuer tout apprentissage à la volée en respectant des contraintes strictes en matière de puissance et de traitement.
Il reste un long chemin à parcourir avant que l'IA puisse fonctionner comme l'homme, c'est-à-dire faire face à une variété infinie de scénarios en constante évolution. Mais si les informaticiens parviennent à mettre au point des techniques permettant aux machines de s'adapter en permanence, comme le font les êtres vivants, cela pourrait contribuer à rendre les systèmes d'IA plus polyvalents, plus précis et d'une intelligence plus reconnaissable.
doi: https://doi.org/10.1038/d41586-022-01962-y
Cet article fait partie de Nature Outlook : Robotique et intelligence artificielle, un supplément indépendant sur le plan éditorial, produit avec le soutien financier de tiers. À propos de ce contenu.
Références
- Patterson, D. et al. Preprint sur https://arxiv.org/abs/2104.10350 (2021).
- Mandivarapu, J. K., Camp, B. & Estrada, R. Front. Artif. Intell. 3, 19 (2020).PubMed Article Google Scholar
- Camp, B., Mandivarapu, J. K. & Estrada, R. Preprint at https://arxiv.org/abs/2011.07035 (2020).
Cet article a été rédigé par Marcus Woo et publié à l'origine dans Nature
Fourchette à la main, un bras robotisé embroche une fraise depuis le haut et l'amène à la bouche de Tyler Schrenk. Assis dans son fauteuil roulant, Schrenk avance son cou pour prendre une bouchée. Le bras s'attaque ensuite à une tranche de banane, puis à une carotte. Chaque mouvement s'effectue de lui-même, sur commande vocale de Schrenk.
Pour M. Schrenk, qui est devenu paralysé à partir du cou après un accident de plongée en 2012, un tel dispositif ferait une énorme différence dans sa vie quotidienne s'il était installé à son domicile. "S'habituer à ce que quelqu'un d'autre me nourrisse a été l'une des choses les plus étranges auxquelles j'ai dû faire face", explique-t-il. "Cela contribuerait sans aucun doute à mon bien-être et à ma santé mentale.
Son domicile est déjà équipé d'interrupteurs et d'ouvre-portes à commande vocale, ce qui lui permet d'être indépendant pendant environ 10 heures par jour sans l'aide d'un soignant. "J'ai été capable de comprendre la plupart des choses", dit-il. "Mais je ne peux pas me nourrir seul. C'est pourquoi il a voulu tester le robot d'alimentation, baptisé ADA (abréviation de "assistive dexterous arm"). Des caméras placées au-dessus de la fourche permettent à ADA de voir ce qu'il doit prendre. Mais pour savoir avec quelle force planter une fourchette dans une banane molle ou une carotte croquante, et avec quelle force saisir l'ustensile, il faut un sens que les humains considèrent comme allant de soi : "Le toucher est essentiel", explique Tapomayukh Bhattacharjee, roboticien à l'université Cornell d'Ithaca, dans l'État de New York, qui a dirigé la conception d'ADA alors qu'il travaillait à l'université de Washington, à Seattle. Les deux doigts du robot sont équipés de capteurs qui mesurent la force latérale (ou de cisaillement) lorsque l'on tient la fourchette.1. Ce système n'est qu'un exemple des efforts croissants déployés pour doter les robots d'un sens du toucher.
Partie de Nature Outlook : Robotique et intelligence artificielle
"Les choses vraiment importantes impliquent la manipulation, impliquent que le robot tende la main et modifie quelque chose dans le monde", explique Ted Adelson, spécialiste de la vision par ordinateur au Massachusetts Institute of Technology (MIT) à Cambridge. Ce n'est qu'avec un retour d'information tactile qu'un robot peut ajuster sa prise pour manipuler des objets de tailles, de formes et de textures différentes. Grâce au toucher, les robots peuvent aider les personnes à mobilité réduite, ramasser des objets mous tels que des fruits, manipuler des matériaux dangereux et même aider à la chirurgie. La détection tactile pourrait également permettre d'améliorer les prothèses, d'aider les gens à rester littéralement en contact à distance, et même de réaliser le fantasme du robot ménager polyvalent qui s'occuperait de la lessive et de la vaisselle. "Si nous voulons des robots chez nous pour nous aider, nous voulons qu'ils soient capables d'utiliser leurs mains", explique M. Adelson. "Et si vous utilisez vos mains, vous avez vraiment besoin d'un sens du toucher.
Avec cet objectif en tête, et portés par les progrès de l'apprentissage automatique, les chercheurs du monde entier développent une myriade de capteurs tactiles, depuis les dispositifs en forme de doigt jusqu'aux peaux électroniques. L'idée n'est pas nouvelle, explique Veronica Santos, roboticienne à l'université de Californie à Los Angeles. Mais les progrès réalisés en matière de matériel, de puissance de calcul et de savoir-faire algorithmique ont dynamisé le secteur. "La détection tactile et la manière de l'intégrer aux robots suscitent un nouvel enthousiasme", explique Veronica Santos.
Sentir par la vue
L'un des capteurs les plus prometteurs repose sur une technologie bien établie : les caméras. Les caméras d'aujourd'hui sont peu coûteuses mais puissantes, et combinées à des algorithmes sophistiqués de vision par ordinateur, elles ont donné naissance à toute une série de capteurs tactiles. Les différents modèles utilisent des techniques légèrement différentes, mais ils interprètent tous le toucher en capturant visuellement la façon dont un matériau se déforme au contact.
L'ADA utilise un capteur à base de caméra appelé GelSight, dont le premier prototype a été conçu par M. Adelson et son équipe il y a plus de dix ans.2. Une lumière et une caméra sont placées derrière un morceau de matériau souple et caoutchouteux, qui se déforme lorsqu'un objet exerce une pression sur lui. La caméra capture alors la déformation avec une sensibilité surhumaine, discernant des bosses aussi petites qu'un micromètre. GelSight peut également évaluer les forces, y compris les forces de cisaillement, en suivant le mouvement d'un motif de points imprimés sur le matériau caoutchouteux lorsqu'il se déforme.2.
GelSight n'est pas le premier ni le seul capteur basé sur une caméra (ADA a été testé avec un autre capteur, appelé FingerVision). Toutefois, sa conception relativement simple et facile à fabriquer l'a distingué jusqu'à présent, explique Roberto Calandra, chercheur à Meta AI (anciennement Facebook AI) à Menlo Park, en Californie, qui a collaboré avec M. Adelson. En 2011, M. Adelson a cofondé une entreprise, également appelée GelSight, basée sur la technologie qu'il a développée. L'entreprise, basée à Waltham, dans le Massachusetts, a concentré ses efforts sur des industries telles que l'aérospatiale, en utilisant la technologie des capteurs pour inspecter les fissures et les défauts sur les surfaces.
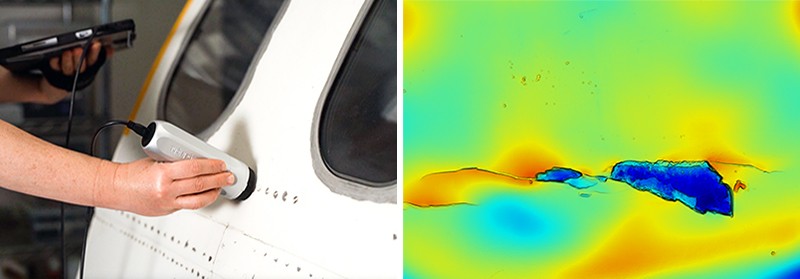
L'un des derniers capteurs à base de caméra s'appelle Insight, documenté cette année par Huanbo Sun, Katherine Kuchenbecker et Georg Martius à l'Institut Max Planck pour les systèmes intelligents à Stuttgart, en Allemagne.3. L'appareil, qui ressemble à un doigt, est constitué d'un dôme souple, opaque, en forme de tente, maintenu par de fines entretoises, qui dissimule une caméra à l'intérieur.
Il n'est pas aussi sensible que GelSight, mais il offre d'autres avantages. GelSight se limite à détecter le contact sur une petite surface plane, alors qu'Insight détecte le contact tout autour du doigt en 3D, explique M. Kuchenbecker. La surface en silicone d'Insight est également plus facile à fabriquer et détermine les forces avec plus de précision. Selon M. Kuchenbecker, la surface intérieure bosselée d'Insight rend les forces plus facilement visibles et, contrairement à la méthode de GelSight qui consiste à déterminer d'abord la géométrie de la surface de caoutchouc déformée puis à calculer les forces en jeu, Insight détermine les forces directement à partir de la façon dont la lumière frappe sa caméra. M. Kuchenbecker pense que cela fait d'Insight une meilleure option pour un robot qui doit saisir et manipuler des objets ; Insight a été conçu pour former les extrémités d'une pince robotique à trois chiffres appelée TriFinger.
Solutions pour la peau
Les capteurs à base de caméra ne sont pas parfaits. Par exemple, ils ne peuvent pas détecter des forces invisibles, telles que l'ampleur de la tension d'une corde ou d'un fil tendu. La fréquence d'images d'une caméra peut également ne pas être assez rapide pour capturer des sensations fugaces, telles qu'une poignée qui glisse, explique M. Santos. Enfin, l'insertion d'un capteur relativement encombrant dans un doigt ou une main de robot, déjà encombré d'autres capteurs ou actionneurs (les composants qui permettent à la main de bouger), peut également poser problème.
C'est l'une des raisons pour lesquelles d'autres chercheurs conçoivent des dispositifs plats et flexibles qui peuvent s'enrouler autour d'un appendice de robot. Zhenan Bao, ingénieur chimiste à l'université Stanford en Californie, conçoit des peaux qui intègrent de l'électronique flexible et reproduisent la capacité du corps à percevoir le toucher. En 2018, par exemple, son groupe a créé une peau qui détecte la direction des forces de cisaillement en imitant la structure bosselée d'une couche de la peau humaine située sous la surface, appelée spinosum4.

Lorsqu'un toucher doux appuie la couche externe de la peau humaine sur les bosses en forme de dôme du spinosum, les récepteurs situés dans les bosses ressentent la pression. Un toucher plus ferme active des récepteurs plus profonds situés sous les bosses, ce qui permet de distinguer un toucher dur d'un toucher doux. Une force latérale est ressentie comme une pression exercée sur le côté des bosses.
La peau électronique de Bao présente également une structure bosselée qui détecte l'intensité et la direction des forces. Chaque bosse d'un millimètre est recouverte de 25 condensateurs qui stockent l'énergie électrique et agissent comme des capteurs individuels. Lorsque les couches sont pressées l'une contre l'autre, la quantité d'énergie stockée change. Selon M. Bao, les capteurs sont si petits qu'un patch de peau électronique peut en contenir un grand nombre, ce qui permet à la peau de détecter les forces avec précision et d'aider un robot à effectuer des manipulations complexes d'un objet.
Pour tester la peau, les chercheurs ont fixé un patch au bout du doigt d'un gant en caoutchouc porté par une main robotisée. La main a pu tapoter le sommet d'une framboise et ramasser une balle de ping-pong sans l'écraser.

Bien que d'autres peaux électroniques ne soient pas aussi denses en capteurs, elles sont généralement plus faciles à fabriquer. En 2020, Benjamin Tee, un ancien étudiant de Bao qui dirige aujourd'hui son propre laboratoire à l'université nationale de Singapour, a mis au point un polymère semblable à une éponge capable de détecter les forces de cisaillement5. De plus, à l'instar de la peau humaine, ce polymère est autocicatrisant : après avoir été déchiré ou coupé, il se ressoude sous l'effet de la chaleur et reste extensible, ce qui est utile pour faire face à l'usure et aux déchirures.
Ce matériau, appelé AiFoam, est doté d'électrodes souples en fil de cuivre qui reproduisent approximativement la répartition des nerfs sur la peau humaine. Lorsqu'on la touche, la mousse se déforme et les électrodes se serrent l'une contre l'autre, ce qui modifie le courant électrique qui la traverse. Cela permet de mesurer à la fois l'intensité et la direction des forces. AiFoam peut même détecter la présence d'une personne juste avant qu'elle n'entre en contact : lorsque son doigt s'approche à quelques centimètres, il abaisse le champ électrique entre les électrodes de la mousse.

En novembre dernier, des chercheurs de Meta AI et de l'université Carnegie Mellon de Pittsburgh, en Pennsylvanie, ont annoncé la création d'une peau sensible au toucher composée d'un matériau caoutchouteux incrusté de particules magnétiques.6. Baptisée ReSkin, cette peau se déforme en même temps que les particules, ce qui modifie le champ magnétique. Elle est conçue pour être facilement remplacée - elle peut être décollée et une nouvelle peau installée sans nécessiter de recalibrage complexe - et 100 capteurs peuvent être produits pour moins de 6 USD.
Plutôt que d'être des outils universels, les différentes peaux et les différents capteurs se prêteront probablement à des usages particuliers. Bhattacharjee et ses collègues, par exemple, ont créé un manchon extensible qui s'adapte à un bras robotique et qui est utile pour détecter les contacts accidentels entre un bras robotique et son environnement7. La feuille est fabriquée à partir d'un tissu stratifié qui détecte les changements de résistance électrique lorsqu'une pression lui est appliquée. Elle ne peut pas détecter les forces de cisaillement, mais elle peut couvrir une large zone et s'enrouler autour des articulations d'un robot.
M. Bhattacharjee utilise le manchon pour identifier non seulement le moment où un bras robotique entre en contact avec quelque chose lorsqu'il se déplace dans un environnement encombré, mais aussi ce contre quoi il se cogne. Si un robot d'assistance dans une maison heurte un rideau alors qu'il cherche un objet, il peut continuer à avancer, mais s'il entre en contact avec un verre à vin fragile, il devra prendre des mesures d'évitement.
D'autres approches utilisent l'air pour donner le sens du toucher. Certains robots utilisent des pinces à succion pour saisir et déplacer des objets dans les entrepôts ou dans les océans. Dans ces cas, Hannah Stuart, ingénieur mécanicien à l'université de Californie à Berkeley, espère que la mesure du flux d'air de succion pourra fournir un retour d'information tactile à un robot. Son groupe a montré que le débit d'air peut déterminer la force de la prise de la pince aspirante et même la rugosité de la surface sur laquelle elle est aspirée.8. Et sous l'eau, il peut révéler comment un objet se déplace lorsqu'il est tenu par une main robotisée à succion9.
Traitement des sentiments
Les technologies tactiles d'aujourd'hui sont diverses, explique Mme Kuchenbecker. "Il existe de nombreuses options réalisables, et les gens peuvent s'appuyer sur le travail des autres", dit-elle. Mais concevoir et fabriquer des capteurs n'est qu'un début. Les chercheurs doivent ensuite les intégrer dans un robot, qui doit alors déterminer comment utiliser les informations d'un capteur pour exécuter une tâche. "C'est en fait la partie la plus difficile", explique M. Adelson.
Pour les peaux électroniques qui contiennent une multitude de capteurs, le traitement et l'analyse des données provenant de chacun d'entre eux nécessiteraient beaucoup de temps de calcul et d'énergie. Pour traiter autant de données, des chercheurs comme M. Bao s'inspirent du système nerveux humain, qui traite aisément un flot constant de signaux. Depuis plus de 30 ans, les informaticiens tentent d'imiter le système nerveux à l'aide d'ordinateurs neuromorphiques. Mais l'objectif de M. Bao est de combiner une approche neuromorphique avec une peau souple qui pourrait s'intégrer au corps de manière transparente, par exemple sur un bras bionique.
Inscrivez-vous à la lettre d'information de Nature sur la robotique et l'IA
Contrairement à d'autres capteurs tactiles, les peaux de Bao transmettent les signaux sensoriels sous forme d'impulsions électriques, comme celles des nerfs biologiques. L'information n'est pas stockée dans l'intensité des impulsions, qui peut diminuer au fur et à mesure que le signal se déplace, mais dans leur fréquence. Par conséquent, le signal ne perd pas beaucoup d'informations à mesure que la portée augmente, explique-t-elle.
Les impulsions provenant de plusieurs capteurs se rencontreraient au niveau de dispositifs appelés transistors synaptiques, qui combineraient les signaux en un modèle d'impulsions, à l'instar de ce qui se passe lorsque les nerfs se rencontrent au niveau des jonctions synaptiques. Ensuite, au lieu de traiter les signaux de chaque capteur, un algorithme d'apprentissage automatique n'a plus qu'à analyser les signaux de plusieurs jonctions synaptiques, en apprenant si ces motifs correspondent, par exemple, au duvet d'un pull ou à l'adhérence d'un ballon.
En 2018, le laboratoire de Bao a intégré cette capacité dans un système nerveux artificiel simple et flexible, capable d'identifier les caractères Braille.10. Fixé à la patte d'un cafard, le dispositif pouvait stimuler les nerfs de l'insecte, démontrant ainsi le potentiel d'un dispositif prothétique pouvant s'intégrer au système nerveux d'une créature vivante.
En fin de compte, pour donner un sens aux données des capteurs, un robot doit s'appuyer sur l'apprentissage automatique. Traditionnellement, le traitement des données brutes d'un capteur était fastidieux et difficile, explique M. Calandra. Pour comprendre les données brutes et les convertir en nombres physiquement significatifs tels que la force, les roboticiens devaient calibrer et caractériser le capteur. Grâce à l'apprentissage automatique, les roboticiens peuvent sauter ces étapes laborieuses. Les algorithmes permettent à un ordinateur de passer au crible une énorme quantité de données brutes et d'identifier lui-même des modèles significatifs. Ces modèles - qui peuvent représenter une prise suffisamment serrée ou une texture rugueuse - peuvent être appris à partir de données d'entraînement ou de simulations informatiques de la tâche prévue, puis appliqués à des scénarios réels.
"Nous venons tout juste de commencer à explorer l'intelligence artificielle pour la détection du toucher", explique M. Calandra. "Nous sommes loin de la maturité d'autres domaines tels que la vision par ordinateur ou le traitement du langage naturel. Les données de vision par ordinateur sont basées sur un réseau bidimensionnel de pixels, une approche que les informaticiens ont exploitée pour développer de meilleurs algorithmes. Mais les chercheurs ne savent toujours pas quelle pourrait être une structure comparable pour les données tactiles. Comprendre la structure de ces données et apprendre à en tirer parti pour créer de meilleurs algorithmes sera l'un des plus grands défis de la prochaine décennie.
Suppression des barrières
L'essor de l'apprentissage automatique et la diversité du matériel émergent sont de bon augure pour l'avenir de la détection tactile. Mais la pléthore de technologies représente également un défi, selon les chercheurs. Étant donné que de nombreux laboratoires disposent de leurs propres prototypes de matériel, de logiciels et même de formats de données, les scientifiques ont du mal à comparer les dispositifs et à s'appuyer sur les travaux des uns et des autres. Et si les roboticiens veulent intégrer pour la première fois la détection tactile dans leur travail, ils devront construire leurs propres capteurs à partir de zéro - une tâche souvent coûteuse et qui ne relève pas nécessairement de leur domaine d'expertise.
Plus d'informations sur les perspectives de la nature
C'est pourquoi, en novembre dernier, GelSight et Meta AI ont annoncé un partenariat pour la fabrication d'un capteur de type caméra au bout du doigt appelé DIGIT. Avec un prix de vente de 300 dollars, le dispositif est conçu pour être un capteur standard, relativement bon marché et prêt à l'emploi, qui peut être utilisé dans n'importe quel robot. "Cela aide sans aucun doute la communauté de la robotique, qui a été freinée par le coût élevé du matériel", explique M. Santos.
En fonction de la tâche, cependant, vous n'avez pas toujours besoin d'un matériel aussi avancé. Dans un article publié en 2019, un groupe du MIT dirigé par Subramanian Sundaram a construit des capteurs en prenant en sandwich quelques couches de matériaux, qui changent de résistance électrique lorsqu'ils sont soumis à une pression.11. Ces capteurs ont ensuite été incorporés dans des gants, pour un coût matériel total de seulement 10 dollars. Avec l'aide de l'apprentissage automatique, même un outil aussi simple que celui-ci peut aider les roboticiens à mieux comprendre les nuances de la préhension, explique Sundaram.
Tous les roboticiens ne sont pas non plus des spécialistes de l'apprentissage automatique. Pour y remédier, Meta AI a mis à la disposition des chercheurs un logiciel open source. "J'espère qu'en ouvrant cet écosystème, nous abaissons la barre d'entrée pour les nouveaux chercheurs qui veulent s'attaquer au problème", explique M. Calandra. "C'est vraiment le début.
Bien que la préhension et la dextérité continuent d'être au cœur de la robotique, la détection tactile ne sert pas qu'à cela. Un robot souple et glissant pourrait avoir besoin de sentir son chemin pour naviguer dans les décombres dans le cadre d'opérations de recherche et de sauvetage, par exemple. Un robot pourrait également avoir besoin de sentir une tape dans le dos : Mme Kuchenbecker et son étudiante Alexis Block ont construit un robot doté de capteurs de couple dans les bras, d'un capteur de pression et d'un microphone à l'intérieur d'un corps souple et gonflable capable de donner une étreinte confortable et agréable, puis de la relâcher lorsque vous la lâchez. Ce type de toucher humain est essentiel pour de nombreux robots qui interagissent avec les personnes, notamment les prothèses, les aides ménagères et les avatars à distance. C'est dans ces domaines que la détection tactile pourrait s'avérer la plus importante, selon M. Santos. "C'est vraiment l'interaction entre l'homme et le robot qui sera le moteur de cette technologie.

Jusqu'à présent, le toucher robotisé est principalement confiné aux laboratoires de recherche. "Le besoin existe, mais le marché n'est pas encore tout à fait là", explique M. Santos. Mais certains de ceux qui ont eu un avant-goût de ce qu'il est possible de faire sont déjà impressionnés. Les essais d'ADA, le robot nourricier de Schrenk, ont donné un aperçu alléchant de l'indépendance. "C'était vraiment cool", dit-il. "C'était un regard sur l'avenir, sur ce qui pourrait être possible pour moi.
doi: https://doi.org/10.1038/d41586-022-01401-y
Cet article fait partie de Nature Outlook : Robotique et intelligence artificielle, un supplément indépendant sur le plan éditorial, produit avec le soutien financier de tiers. À propos de ce contenu.
Références
- Song, H., Bhattacharjee, T. & Srinivasa, S. S. 2019 International Conference on Robotics and Automation 8367-8373 (IEEE, 2019).Google Scholar
- Yuan, W., Dong, S. & Adelson, E. H. Sensors 17, 2762 (2017).Article Google Scholar
- Sun, H., Kuchenbecker, K. J. & Martius, G. Nature Mach. Intell. 4, 135-145 (2022).Article Google Scholar
- Boutry, C. M. et al. Sci. Robot. 3, aau6914 (2018).Article Google Scholar
- Guo, H. et al. Nature Commun. 11, 5747 (2020).PubMed Article Google Scholar
- Bhirangi, R., Hellebrekers, T., Majidi, C. & Gupta, A. Preprint sur http://arxiv.org/abs/2111.00071 (2021).
- Wade, J., Bhattacharjee, T., Williams, R. D. & Kemp, C. C. Robot. Auton. Syst. 96, 1-14 (2017).Article Google Scholar
- Huh, T. M. et al. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems 1786-1793 (IEEE, 2021).Google Scholar
- Nadeau, P., Abbott, M., Melville, D. & Stuart, H. S. 2020 IEEE International Conference on Robotics and Automation 3701-3707 (IEEE, 2020).Google Scholar
- Kim, Y. et al. Science 360, 998-1003 (2018).PubMed Article Google Scholar
- Sundaram, S. et al. Nature 569, 698-702 (2019).PubMed Article Google Scholar